
John Smith John Smith
0 Course Enrolled • 0 Course CompletedBiography
Databricks Databricks-Generative-AI-Engineer-Associate Questions - Get Verified Databricks-Generative-AI-Engineer-Associate Dumps (2026)
2026 Latest DumpStillValid Databricks-Generative-AI-Engineer-Associate PDF Dumps and Databricks-Generative-AI-Engineer-Associate Exam Engine Free Share: https://drive.google.com/open?id=1Zn6_qYUD38lz08if0gVbp1c6UiXaa-G6
As we all know that the better the products are, the more proffesional the according services are. So are our Databricks-Generative-AI-Engineer-Associate exam braindumps! Not only we provide the most effective Databricks-Generative-AI-Engineer-Associate study guide, but also we offer 24 hours online service to give our worthy customers Databricks-Generative-AI-Engineer-Associate guides and suggestions. Your time will be largely saved for our workers know about our Databricks-Generative-AI-Engineer-Associate practice materials better. Trust us and give yourself a chance to success!
Databricks Databricks-Generative-AI-Engineer-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
>> Databricks-Generative-AI-Engineer-Associate Exam Simulations <<
Pass Guaranteed Quiz 2026 Databricks-Generative-AI-Engineer-Associate: High Hit-Rate Databricks Certified Generative AI Engineer Associate Exam Simulations
A steadily rising competition has been noted in the tech field. Countless candidates around the globe aspire to be Databricks Certified Generative AI Engineer Associate in this field. Databricks Databricks-Generative-AI-Engineer-Associate stand out from the rest of the Databricks professionals. Once you become Databricks certified, a whole new scope opens up to you and you are immediately hired by reputed firms. Even though the Databricks Certified Generative AI Engineer Associate boosts your career options, you have to pass the Databricks-Generative-AI-Engineer-Associate Exam. This Databricks Certified Generative AI Engineer Associate exam serves to filter out the capable from incapable candidates.
Databricks Certified Generative AI Engineer Associate Sample Questions (Q32-Q37):
NEW QUESTION # 32
A Generative Al Engineer is setting up a Databricks Vector Search that will lookup news articles by topic within 10 days of the date specified An example query might be "Tell me about monster truck news around January 5th 1992". They want to do this with the least amount of effort.
How can they set up their Vector Search index to support this use case?
- A. Split articles by 10 day blocks and return the block closest to the query.
- B. Create separate indexes by topic and add a classifier model to appropriately pick the best index.
- C. pass the query directly to the vector search index and return the best articles.
- D. Include metadata columns for article date and topic to support metadata filtering.
Answer: D
Explanation:
The task is to set up a Databricks Vector Search index for news articles, supporting queries like "monster truck news around January 5th, 1992," with minimal effort. The index must filter by topic and a 10-day date range. Let's evaluate the options.
Option A: Split articles by 10-day blocks and return the block closest to the query Pre-splitting articles into 10-day blocks requires significant preprocessing and index management (e.g., one index per block). It's effort-intensive and inflexible for dynamic date ranges.
Databricks Reference: "Static partitioning increases setup complexity; metadata filtering is preferred" ("Databricks Vector Search Documentation").
Option B: Include metadata columns for article date and topic to support metadata filtering Adding date and topic as metadata in the Vector Search index allows dynamic filtering (e.g., date ± 5 days, topic = "monster truck") at query time. This leverages Databricks' built-in metadata filtering, minimizing setup effort.
Databricks Reference: "Vector Search supports metadata filtering on columns like date or category for precise retrieval with minimal preprocessing" ("Vector Search Guide," 2023).
Option C: Pass the query directly to the vector search index and return the best articles Passing the full query (e.g., "Tell me about monster truck news around January 5th, 1992") to Vector Search relies solely on embeddings, ignoring structured filtering for date and topic. This risks inaccurate results without explicit range logic.
Databricks Reference: "Pure vector similarity may not handle temporal or categorical constraints effectively" ("Building LLM Applications with Databricks").
Option D: Create separate indexes by topic and add a classifier model to appropriately pick the best index Separate indexes per topic plus a classifier model adds significant complexity (index creation, model training, maintenance), far exceeding "least effort." It's overkill for this use case.
Databricks Reference: "Multiple indexes increase overhead; single-index with metadata is simpler" ("Databricks Vector Search Documentation").
Conclusion: Option B is the simplest and most effective solution, using metadata filtering in a single Vector Search index to handle date ranges and topics, aligning with Databricks' emphasis on efficient, low-effort setups.
NEW QUESTION # 33
A Generative Al Engineer is using an LLM to classify species of edible mushrooms based on text descriptions of certain features. The model is returning accurate responses in testing and the Generative Al Engineer is confident they have the correct list of possible labels, but the output frequently contains additional reasoning in the answer when the Generative Al Engineer only wants to return the label with no additional text.
Which action should they take to elicit the desired behavior from this LLM?
- A. Use zero shot prompting to instruct the model on expected output format
- B. Use few snot prompting to instruct the model on expected output format
- C. Use a system prompt to instruct the model to be succinct in its answer
- D. Use zero shot chain-of-thought prompting to prevent a verbose output format
Answer: C
Explanation:
The LLM classifies mushroom species accurately but includes unwanted reasoning text, and the engineer wants only the label. Let's assess how to control output format effectively.
Option A: Use few shot prompting to instruct the model on expected output format Few-shot prompting provides examples (e.g., input: description, output: label). It can work but requires crafting multiple examples, which is effort-intensive and less direct than a clear instruction.
Databricks Reference: "Few-shot prompting guides LLMs via examples, effective for format control but requires careful design" ("Generative AI Cookbook").
Option B: Use zero shot prompting to instruct the model on expected output format Zero-shot prompting relies on a single instruction (e.g., "Return only the label") without examples. It's simpler than few-shot but may not consistently enforce succinctness if the LLM's default behavior is verbose.
Databricks Reference: "Zero-shot prompting can specify output but may lack precision without examples" ("Building LLM Applications with Databricks").
Option C: Use zero shot chain-of-thought prompting to prevent a verbose output format Chain-of-Thought (CoT) encourages step-by-step reasoning, which increases verbosity-opposite to the desired outcome. This contradicts the goal of label-only output.
Databricks Reference: "CoT prompting enhances reasoning but often results in detailed responses" ("Databricks Generative AI Engineer Guide").
Option D: Use a system prompt to instruct the model to be succinct in its answer A system prompt (e.g., "Respond with only the species label, no additional text") sets a global instruction for the LLM's behavior. It's direct, reusable, and effective for controlling output style across queries.
Databricks Reference: "System prompts define LLM behavior consistently, ideal for enforcing concise outputs" ("Generative AI Cookbook," 2023).
Conclusion: Option D is the most effective and straightforward action, using a system prompt to enforce succinct, label-only responses, aligning with Databricks' best practices for output control.
NEW QUESTION # 34
A Generative Al Engineer has already trained an LLM on Databricks and it is now ready to be deployed.
Which of the following steps correctly outlines the easiest process for deploying a model on Databricks?
- A. Save the model along with its dependencies in a local directory, build the Docker image, and run the Docker container
- B. Log the model as a pickle object, upload the object to Unity Catalog Volume, register it to Unity Catalog using MLflow, and start a serving endpoint
- C. Wrap the LLM's prediction function into a Flask application and serve using Gunicorn
- D. Log the model using MLflow during training, directly register the model to Unity Catalog using the MLflow API, and start a serving endpoint
Answer: D
NEW QUESTION # 35
A Generative Al Engineer is tasked with developing a RAG application that will help a small internal group of experts at their company answer specific questions, augmented by an internal knowledge base. They want the best possible quality in the answers, and neither latency nor throughput is a huge concern given that the user group is small and they're willing to wait for the best answer. The topics are sensitive in nature and the data is highly confidential and so, due to regulatory requirements, none of the information is allowed to be transmitted to third parties.
Which model meets all the Generative Al Engineer's needs in this situation?
- A. BGE-large
- B. Dolly 1.5B
- C. OpenAI GPT-4
- D. Llama2-70B
Answer: A
Explanation:
Problem Context: The Generative AI Engineer needs a model for a Retrieval-Augmented Generation (RAG) application that provides high-quality answers, where latency and throughput are not major concerns. The key factors areconfidentialityandsensitivityof the data, as well as the requirement for all processing to be confined to internal resources without external data transmission.
Explanation of Options:
* Option A: Dolly 1.5B: This model does not typically support RAG applications as it's more focused on image generation tasks.
* Option B: OpenAI GPT-4: While GPT-4 is powerful for generating responses, its standard deployment involves cloud-based processing, which could violate the confidentiality requirements due to external data transmission.
* Option C: BGE-large: The BGE (Big Green Engine) large model is a suitable choice if it is configured to operate on-premises or within a secure internal environment that meets regulatory requirements.
Assuming this setup, BGE-large can provide high-quality answers while ensuring that data is not transmitted to third parties, thus aligning with the project's sensitivity and confidentiality needs.
* Option D: Llama2-70B: Similar to GPT-4, unless specifically set up for on-premises use, it generally relies on cloud-based services, which might risk confidential data exposure.
Given the sensitivity and confidentiality concerns,BGE-largeis assumed to be configurable for secure internal use, making it the optimal choice for this scenario.
NEW QUESTION # 36
A Generative AI Engineer I using the code below to test setting up a vector store: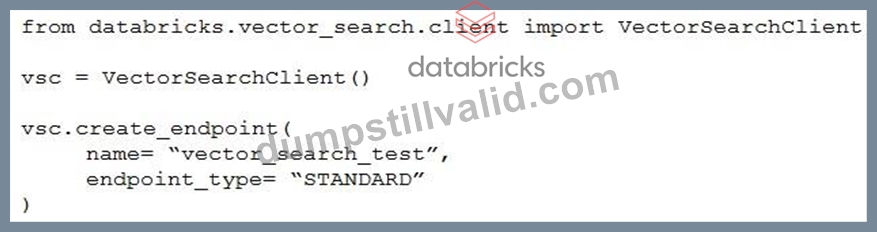
Assuming they intend to use Databricks managed embeddings with the default embedding model, what should be the next logical function call?
- A. vsc.create_direct_access_index()
- B. vsc.get_index()
- C. vsc.create_delta_sync_index()
- D. vsc.similarity_search()
Answer: C
Explanation:
* Context: The Generative AI Engineer is setting up a vector store using Databricks' VectorSearchClient. This is typically done to enable fast and efficient retrieval of vectorized data for tasks like similarity searches.
* Explanation of Options:
Option A: vsc.get_index(): This function would be used to retrieve an existing index, not create one, so it would not be the logical next step immediately after creating an endpoint.
Option B: vsc.create_delta_sync_index(): After setting up a vector store endpoint, creating an index is necessary to start populating and organizing the data. The create_delta_sync_index() function specifically creates an index that synchronizes with a Delta table, allowing automatic updates as the data changes. This is likely the most appropriate choice if the engineer plans to use dynamic data that is updated over time.
Option C: vsc.create_direct_access_index(): This function would create an index that directly accesses the data without synchronization. While also a valid approach, it's less likely to be the next logical step if the default setup (typically accommodating changes) is intended.
Option D: vsc.similarity_search(): This function would be used to perform searches on an existing index; however, an index needs to be created and populated with data before any search can be conducted.
Given the typical workflow in setting up a vector store, the next step after creating an endpoint is to establish an index, particularly one that synchronizes with ongoing data updates, hence Option B.
NEW QUESTION # 37
......
If you don't prepare with real Databricks-Generative-AI-Engineer-Associate questions, you fail, lose time and money. DumpStillValid product is specially designed to help you pass the exam on the first try. The study material is easy to use. You can choose from 3 different formats available according to your needs. The 3 formats are Databricks Databricks-Generative-AI-Engineer-Associate desktop practice test software, browser based practice exam, and PDF.
New Databricks-Generative-AI-Engineer-Associate Braindumps Pdf: https://www.dumpstillvalid.com/Databricks-Generative-AI-Engineer-Associate-prep4sure-review.html
- Latest Databricks-Generative-AI-Engineer-Associate Exam Materials 🥉 Databricks-Generative-AI-Engineer-Associate Valid Dumps 👗 Databricks-Generative-AI-Engineer-Associate Cheap Dumps 🛢 Search for ▷ Databricks-Generative-AI-Engineer-Associate ◁ and obtain a free download on ➠ www.testkingpass.com 🠰 🦺Databricks-Generative-AI-Engineer-Associate Reliable Braindumps
- Latest Databricks-Generative-AI-Engineer-Associate Exam Materials 🌴 Databricks-Generative-AI-Engineer-Associate Cheap Dumps 🚃 Databricks-Generative-AI-Engineer-Associate Exam Collection 🛳 Copy URL 《 www.pdfvce.com 》 open and search for ▛ Databricks-Generative-AI-Engineer-Associate ▟ to download for free 🔘Databricks-Generative-AI-Engineer-Associate Exam Collection
- Relevant Databricks-Generative-AI-Engineer-Associate Exam Dumps 🧩 Latest Databricks-Generative-AI-Engineer-Associate Exam Materials 🤽 Latest Databricks-Generative-AI-Engineer-Associate Test Camp 🌷 Copy URL [ www.dumpsmaterials.com ] open and search for 【 Databricks-Generative-AI-Engineer-Associate 】 to download for free 🏢Databricks-Generative-AI-Engineer-Associate Boot Camp
- Databricks-Generative-AI-Engineer-Associate Cheap Dumps 🎴 Pdf Databricks-Generative-AI-Engineer-Associate Version 😚 Databricks-Generative-AI-Engineer-Associate Cheap Dumps 🟪 ✔ www.pdfvce.com ️✔️ is best website to obtain ⮆ Databricks-Generative-AI-Engineer-Associate ⮄ for free download 🌻Databricks-Generative-AI-Engineer-Associate Exam
- Three Easy and User-Friendly www.prepawayexam.com Databricks Databricks-Generative-AI-Engineer-Associate Exam Question Formats ⏮ Go to website ( www.prepawayexam.com ) open and search for “ Databricks-Generative-AI-Engineer-Associate ” to download for free 🐲Databricks-Generative-AI-Engineer-Associate Guaranteed Success
- Databricks-Generative-AI-Engineer-Associate Cheap Dumps 🍋 Latest Databricks-Generative-AI-Engineer-Associate Exam Materials ⏳ Databricks-Generative-AI-Engineer-Associate Exam 🔘 Download ▷ Databricks-Generative-AI-Engineer-Associate ◁ for free by simply entering ▷ www.pdfvce.com ◁ website 📍Databricks-Generative-AI-Engineer-Associate Reliable Braindumps
- Pass Guaranteed Quiz Databricks - Databricks-Generative-AI-Engineer-Associate - The Best Databricks Certified Generative AI Engineer Associate Exam Simulations 🐡 Copy URL 【 www.troytecdumps.com 】 open and search for ▛ Databricks-Generative-AI-Engineer-Associate ▟ to download for free 🍤Databricks-Generative-AI-Engineer-Associate Cheap Dumps
- Databricks-Generative-AI-Engineer-Associate Boot Camp 🧜 New Exam Databricks-Generative-AI-Engineer-Associate Braindumps 📣 Databricks-Generative-AI-Engineer-Associate Reliable Braindumps 💒 Download ☀ Databricks-Generative-AI-Engineer-Associate ️☀️ for free by simply searching on ⮆ www.pdfvce.com ⮄ 📤New Exam Databricks-Generative-AI-Engineer-Associate Braindumps
- 100% Free Databricks-Generative-AI-Engineer-Associate – 100% Free Exam Simulations | Updated New Databricks Certified Generative AI Engineer Associate Braindumps Pdf 🧥 Download ( Databricks-Generative-AI-Engineer-Associate ) for free by simply searching on ▶ www.practicevce.com ◀ ⏭Databricks-Generative-AI-Engineer-Associate Exam Dumps Free
- Questions and Answers for the Databricks-Generative-AI-Engineer-Associate Exam, Authentic 2026 😎 Search for ➠ Databricks-Generative-AI-Engineer-Associate 🠰 and obtain a free download on { www.pdfvce.com } 🥑Databricks-Generative-AI-Engineer-Associate Exam Dumps Free
- Databricks-Generative-AI-Engineer-Associate Valid Dumps 🧡 Databricks-Generative-AI-Engineer-Associate Valid Dumps ⏩ Databricks-Generative-AI-Engineer-Associate New Dumps Free 🚺 Open ( www.examcollectionpass.com ) and search for ✔ Databricks-Generative-AI-Engineer-Associate ️✔️ to download exam materials for free 🌸Valid Databricks-Generative-AI-Engineer-Associate Guide Files
- shaniapzhy095011.bloggip.com, mayabtuz987386.theideasblog.com, www.stes.tyc.edu.tw, theresaabwc741244.buscawiki.com, shaniapste750219.blogoxo.com, amaanfovk805844.wikilima.com, qoos-step.com, lingeriebookmark.com, ezmarkbookmarks.com, jaspernnqu638184.bloggazzo.com, Disposable vapes
What's more, part of that DumpStillValid Databricks-Generative-AI-Engineer-Associate dumps now are free: https://drive.google.com/open?id=1Zn6_qYUD38lz08if0gVbp1c6UiXaa-G6